
Small Language Models (SLMs) are streamlined versions of large language models or LLMs like GPT-4. With fewer parameters under the hood, they’re faster, more affordable, and easier to run, especially on devices with limited computing power like smartphones or edge devices. While they don’t pack the same punch as full-scale LLMs, SLMs shine in focused tasks like text classification, summarization, or powering chatbots, where heavyweight models might be overkill.
A Small Language Models is a Generative AI technology similar to a large language model but with a significantly reduced size. In general, LLMs are generalists and SLMs are specialists.1
In this blog post, we’ll take a closer look at what SLMs are, explore their practical use cases, and weigh their pros and cons.
The Shift Toward Smaller Models
Over the past few years, LLMs like GPT-4 have completely changed the way we think about integrating AI into software. But now that the initial hype is dying down and we’re getting into the real work of building, a lot of teams are realizing something important: not every use case needs the power and cost of a massive model.
That’s where Small Language Models come into play.
SLMs are lightweight and efficient, designed to handle specific tasks with impressive performance. They may not have the broad capabilities or deep reasoning skills of larger models, but their speed, portability, and privacy benefits make them an increasingly practical choice for real-world use.
From a solution architecture standpoint, the growing interest in SLMs is fueled by three key factors as following.

Latency and Cost Increasing: Running inference with a LLM can be too slow or costly for many real-world applications, especially when scaling up. Small Language Models , on the other hand, can run locally or in lightweight containers and respond in just milliseconds.
Edge or Offline Scenarios: SLMs bring intelligent capabilities to edge devices, like IoT sensors or mobile apps, even without an internet connection. On the other hand, Large Language Models can technically run offline, but they usually don’t, because they’re massive.
Data Privacy and Control: Hosting an SLM in-house gives teams more control over how data is handled, ensuring better compliance and easier auditing, especially important in highly regulated industries.
In short, we’re entering an era where just enough intelligence can be more valuable than aiming for maximum intelligence. For software architects, it’s a reminder that sometimes thinking smaller is just as important as thinking big.
Anatomy of an SLM
To build effectively with Small Language Models, developers and architects need to understand what actually makes a model small. From an architect’s perspective, building with SLMs is all about navigating trade-offs thoughtfully and strategically. It’s not just about having fewer parameters; it’s about making smart, intentional decisions around non-functional requirements.
At a high level, SLMs are compact neural language models, often derived from larger models through techniques like distillation, quantization, or architectural pruning. These methods aim to retain as much task-specific performance as possible while dramatically reducing resource requirements.
SLMs have four key characteristics, which are outlined below:
- Smaller Model Size: Usually under 1 billion parameters in SLMs, compared to the 7 billion (or more) found in most large language models.
- Lightweight and Efficient: Designed to run smoothly on everyday hardware; think consumer GPUs, mobile devices, or even standard CPUs.
- Fast and Optimized: Built for quick responses, especially when compressed to 8-bit or 4-bit formats.
- Purpose-Built: Typically fine-tuned for specific tasks like classification, summarization, or intent detection, rather than broad, open-ended reasoning.
Smaller models don’t just lower costs, but they offer greater flexibility in how and where you deploy them. You can run them as microservices, use them offline, or deploy them at the edge. They’re also easier to integrate into existing CI/CD and MLOps pipelines.
In many cases, Small Language Models deliver good enough intelligence for production workloads, especially when combined with high-quality data or an effective retrieval system.
Use Cases & Design Patterns
Small Language Models aren’t just stripped-down versions of large language models. They’re a smart, strategic choice for many software applications where bigger isn’t necessarily better. For architects and developers, this shift introduces new design patterns that prioritize performance, cost-efficiency, and flexible deployment.
Here are a few areas where SLMs are already making a real difference.

Smart Assistants
In customer support systems or internal IT help desks, SLMs can handle tasks like understanding user intent, matching FAQs, and even filling out forms, without the need for expensive LLM APIs. This approach cuts down on cloud dependency and keeps data processing more local.
Pattern
SLM for Intent Classification + Rule-Based Action, If SLM is uncertain then fallback to LLM
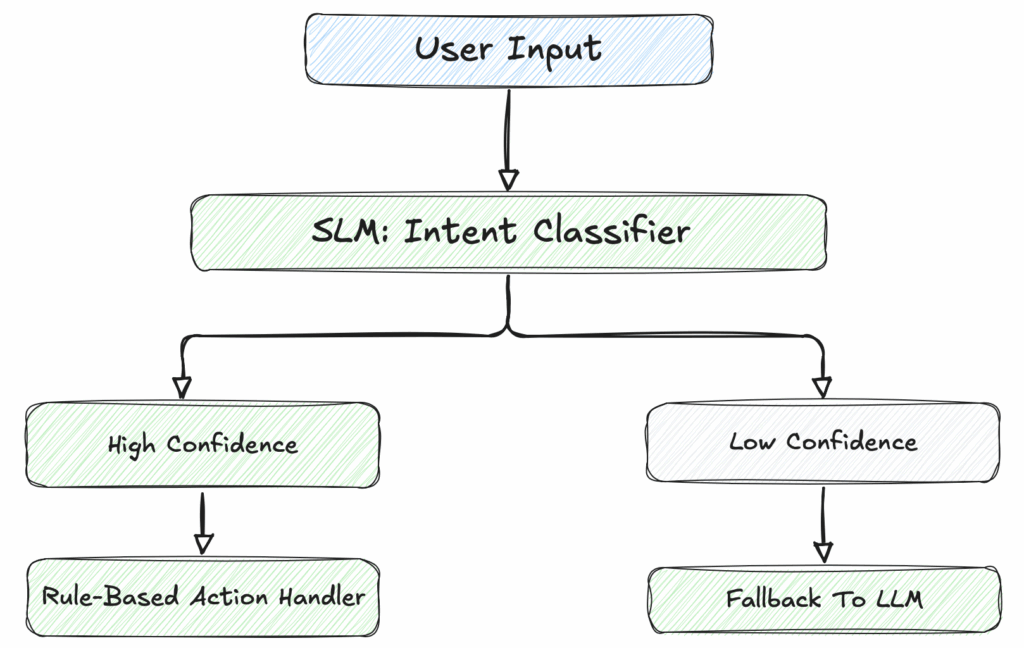
Embedded Intelligence
SLMs are compact enough to run directly on devices like mobile phones, industrial IoT hubs, or even point-of-sale terminals. This means they can handle tasks like speech tagging, command parsing, or real-time transcription, without needing to send any data to the cloud.
Pattern
Edge-deployed SLM + local cache → If yes then instant feedback (low latency); Else Feedback to LLM
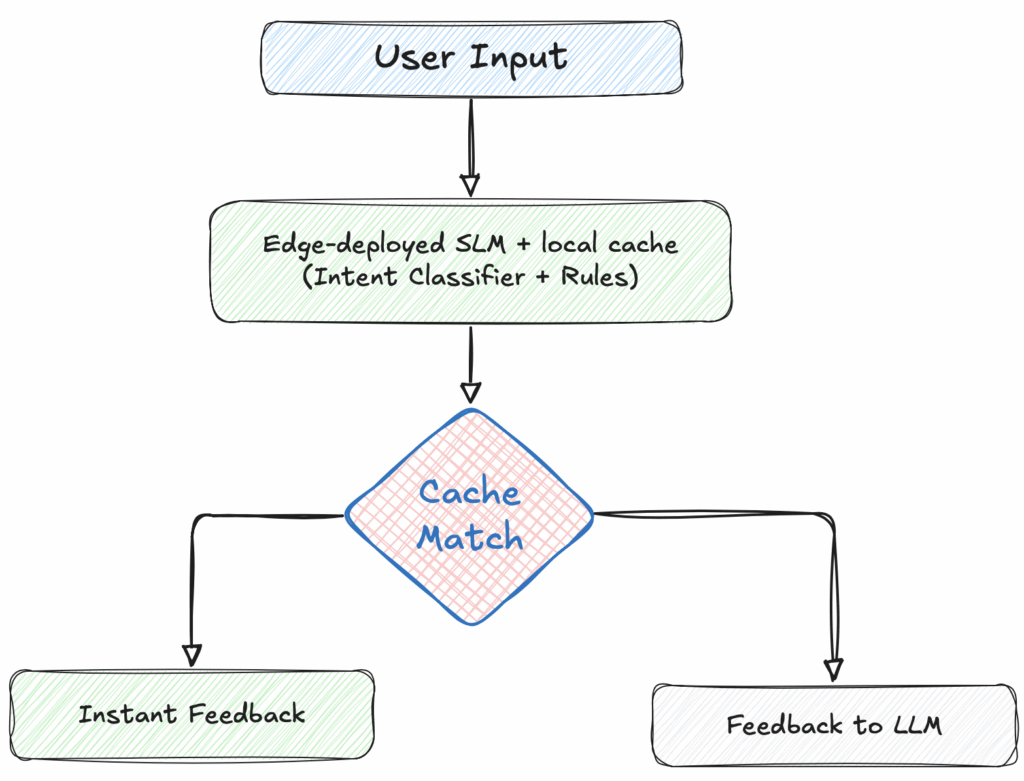
CI/CD & DevOps
SLMs can be built into developer tools to offer contextual suggestions, generate commit messages, summarize code, and explain errors, all without sending sensitive code to external APIs.
or example, an SLM integrated into a code editor could help by suggesting better variable names, writing commit messages, explaining error messages, or even summarizing blocks of code, all while keeping your work secure and private.
Pattern
Locally hosted Small Language Models (like TinyLLaMA or MiniLM) performs real-time inference, then → real-time inference is used by a CI pipeline or an editor.
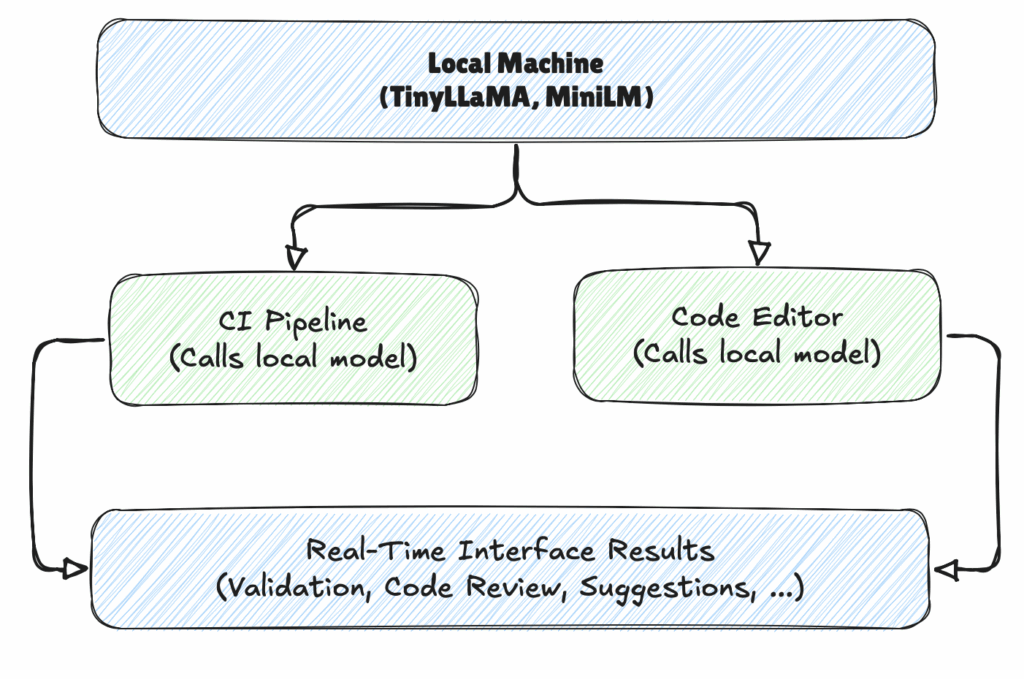
Retrieval-Augmented Generation (RAG) Boosters
Even in systems powered by large LLMs, Small Language Models can play an important role. They can preprocess queries or classify user intents. By handling these lightweight tasks upfront, SLMs help reduce the workload on the core LLM and speed up the entire pipeline.
Pattern
SLM handles query classification & document re-ranking, then → LLM focuses on final synthesis
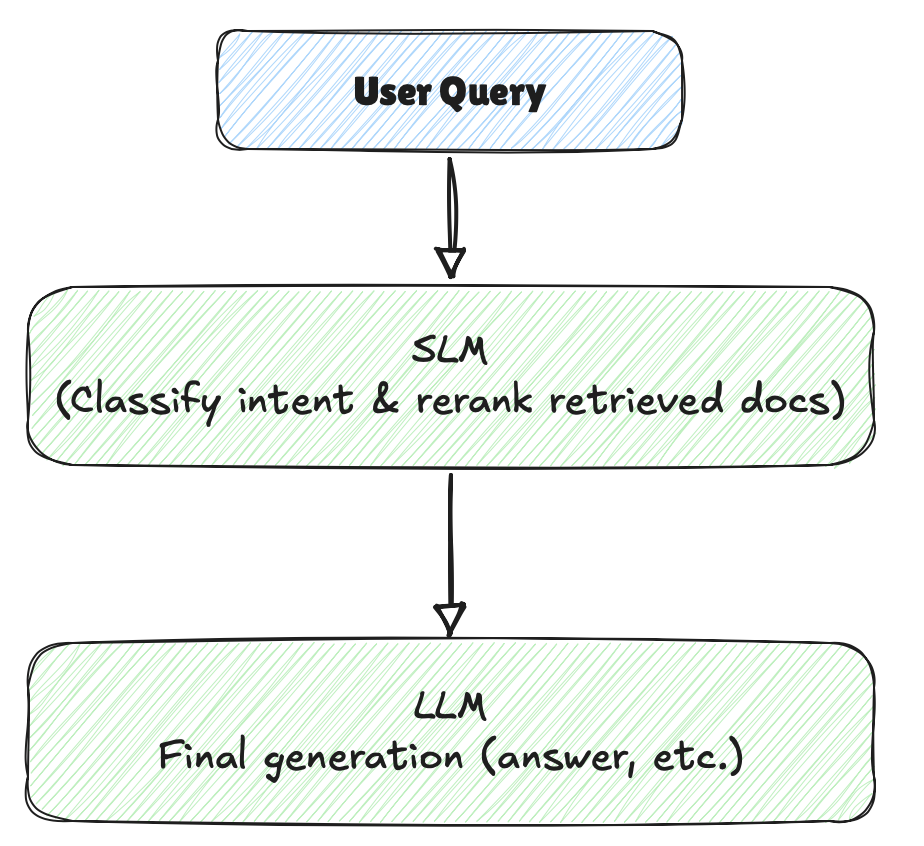
In short, Small Language Models add a new layer to the AI toolkit: good enough intelligence for situations where cost, speed, or trust are critical constraints. By designing systems with a hybrid approach, using SLMs for practical tasks and LLMs for creative ones, we can build smarter, faster, and more scalable solutions.
Architecting with SLMs (Deployment, Tooling, and …)
Once we understand where Small Language Models fit in, the next challenge is figuring out how to integrate them effectively into modern software architectures. SLMs are reshaping how we think about model serving, scalability, and the overall developer experience.
Here’s a breakdown three of key architectural considerations.
Deployment Strategies
On-Device Deployment is a deployment strategy that uses SLMs. It involves deploying models directly onto devices like smartphones, IoT hardware, or desktop computers, for example, running MobileBERT within a mobile app. This approach is especially valuable for applications that prioritize privacy or even need to function without an internet connection.
Another architectural strategy for using SLMs is to wrap them in Docker containers and deploy them as independent microservices, what we refer to as Containerized Services. This approach allows inference tasks to scale independently from the main application back-end.
Additionally, you can deploy SLMs using Serverless Runtimes like AWS Lambda or Azure Functions, or on edge platforms such as Cloudflare Workers AI. This allows for fast, sub-second responses delivered close to where your users are.
Performance Optimization Tactics
To achieve production-grade performance from Small Language Models, consider the following best practices:
- Quantize models to lower precision (such as 8-bit or 4-bit) to reduce memory and computation requirements, while maintaining acceptable accuracy.
- Batch inference requests when operating at scale to improve throughput and reduce compute overhead.
- Leverage GPU or TPU acceleration when available for faster processing, but ensure there’s a reliable fallback to CPU when needed.
- Cache frequent inference results especially for common classification tasks, to enable near-instant responses.
Tooling and Frameworks
To achieve efficient and production-ready deployment of Small Language Models, several tools and frameworks are available, each serving a specific purpose:
- Hugging Face Transformers is widely used for fine-tuning, loading, and serving pre-trained SLMs, making it a go-to library for many developers.
- ONNX Runtime enables high-speed inference and supports multiple hardware platforms, which is essential for scalable deployment.
- Ollama is a lightweight local model runner specifically designed for small models, making it ideal for on-device or resource-constrained environments.
- vLLM offers optimized model serving with a focus on low-latency inference, which is crucial for real-time applications.
- TensorRT, developed by NVIDIA, provides advanced model acceleration and quantization, especially when working with NVIDIA GPUs.
- SentenceTransformers is tailored for generating embedding efficiently, which is particularly useful in semantic search and other similarity-based tasks.
Architectural Patterns With SLMs
SLMs can either enhance or replace traditional components. Here are some useful and relevant patterns.

SLMs as Microservice is an architectural pattern that encapsulates Small Language Models within independent, containerized services to handle scalable and isolated inference tasks. This approach promotes modularity and simplifies deployment across heterogeneous environments, enabling developers to update or replace specific models without impacting the broader system.
The Sidecar SLM Inference architectural pattern in Kubernetes involves deploying a SLM as a sidecar container within the same pod as the primary application. This approach ensures low-latency inference by colocating the model with the application, reducing the need for external API calls or network overhead. It also enables modular updates, as the SLM sidecar can be independently versioned and deployed without affecting the main application logic.
The Hybrid LLM + SLM is an architectural pattern designed for cost-sensitive Retrieval-Augmented Generation or assistant applications that balances performance with efficiency. As it is described above, in this setup, a SLM handles the majority of routine queries, document routing, or retrieval tasks due to its speed and lower cost, while LLM is selectively invoked for complex reasoning, nuanced generation, or high-value outputs.
Wrapping Up
As language models become a core part of modern software stacks, Small Language Models are emerging as a practical, powerful alternative to their larger counterparts. While they don’t match large language models in scale or deep reasoning, SLMs shine where it counts for real-world applications: speed, cost-efficiency, portability, and privacy.
It’s time we stop seeing Small Language Models as second-tier and start recognizing them as foundational.
For software architects and developers, this represents a shift in how we approach AI integration. SLMs can now be treated as first-class components—deployed as microservices, embedded in client apps, or combined with LLMs in layered, hybrid architectures.
As the demand for intelligent features continues to grow, architectures that combine just-enough intelligence with architectural pragmatism will win. Small Language Models may be compact, but their influence on design patterns, developer workflows, and operational flexibility is anything but minor.


