
The Intelligence Dilemma
With breakthroughs like GPT-4, it’s no surprise that Large Language Models (LLMs) have captured so much attention. Their ability to reason, generate text, translate languages, and summarize information with impressive fluency makes them incredibly powerful tools across many fields.
But behind all that capability lies a key architectural trade-off. These models tend to be:
- Resource Hungry
- Sensitive to Latency
- Heavily Reliant on the Cloud
As organizations shift from prototyping to full-scale production, they often run into significant challenges such as financial, technical, and operational. LLMs typically require high-throughput APIs or costly GPU clusters, which can lead to external dependencies and inconsistent performance, especially under heavy workloads.
Many are starting to realize that being intelligent enough often matters more than being the most intelligent. That’s where Small Language Models (SLMs) shine. While they don’t match the broad generative capabilities of LLMs, they offer real advantages in speed, cost, and simplicity.
For tasks like intent detection, document ranking, embedding generation, and basic summarization, small models are more than capable.
We’re facing a growing architectural challenge: how can we tap into the power of LLMs without getting bogged down by their limitations? The solution isn’t black and white. Rather than choosing between big and small models, the emerging trend is hybrid intelligence, smartly blending LLMs with SLMs to build AI systems that are scalable, cost-efficient, and more resilient.
Enter SLM – Small but Strategic
Small Language Models (SLMs) are rapidly becoming a key part of the modern AI architect’s toolkit. While the spotlight often shines on large models, SLMs are quietly powering real-world solutions behind the scenes. They might not write essays or compose poetry, but they’re incredibly effective at focused tasks like classification, vector embedding, summarization, and command parsing, which delivering speed, efficiency, and precision where it counts.
AI isn’t just about maximum intelligence anymore. It’s about intelligence you can actually deploy.
What makes SLMs so compelling is their flexibility in where and how they can be deployed. Models like DistilBERT1, MiniLM, and MobileBERT are specifically designed to meet engineering constraints while maintaining strong performance. Thanks to their lightweight design, they can be easily containerized, versioned, and scaled just like any other microservices.
In modern ecosystems, SLMs serve as the first line of processing. They filter inputs, generate embeddings, or make quick decisions before passing tasks on to a Large Language Model. Instead of replacing LLMs, SLMs work alongside them. When used strategically, they help reduce costs, improve system responsiveness, and minimize reliance on external models.
SLM + LLM in Harmony – Hybrid is Future
The idea of combining Small Language Models with Large Language Model isn’t just a clever workaround. It’s emerging as a thoughtful and strategic design choice. Hybrid AI systems are designed to balance performance and efficiency, using SLMs for quick, routine tasks and turning to LLMs when deeper reasoning or context is needed.
It’s NOT about replacing one with the other, but about orchestrating both to play to their strengths.
In hybrid solutions, SLMs serve as the first line of response. They help by quickly processing information and narrowing down the scope of the problem. Once the context is clear, the LLM takes over to handle deeper analysis, generate content, or provide more comprehensive understanding. We’re also seeing this hybrid model play out across a range of enterprise use cases:
- In Retrieval-Augmented Generation, for example, a SLM often handles embedding and retrieval, while a LLM generates the final response.
- In DevOps workflows, an SLM might classify a code snippet or log entry, with the LLM then suggesting a potential fix.
- In Privacy-Sensitive Environments, SLMs run inference locally, ensuring that only anonymized or aggregated data gets passed to the LLM.
Hybrid Solution is NOT just a technical choice, but a design philosophy.
Hybrid systems offer modularity, better visibility, and more control over costs. They let you scale intelligence itself, not just the models behind it. Furthermore, in a world where AI needs to be everywhere yet fade into the background, hybrid design is emerging as the most scalable, sustainable way forward.
Pros & Cons of Hybrid AI Architectures
Adopting a hybrid AI architecture that blends Small Language Models with Large Language Models can offer powerful strategic advantages. But like any architectural decision, it comes with its own set of trade-offs, particularly around design and operational complexity.
Here are some key pros and cons that architects and developers should keep in mind:

Cost Efficiency: SLMs are great for handling high-volume, lightweight tasks, such as classification, embedding, and filtering, at a much lower cost than using a full-scale LLM. By letting SLMs handle the initial processing or routing of queries, systems can significantly cut down on the more expensive use of LLMs.

Architectural Complexity: Using a hybrid approach adds more services, interfaces, and communication between components. This can increase the mental burden on developers and make things like monitoring, debugging, and deploying updates more complicated.
Performance and Latency: SLMs are designed to run efficiently on edge devices or standard CPUs. This makes them well-suited for real-time applications where speed and responsiveness are crucial, like chatbots, IoT, or mobile apps.
Consistency and Tuning: SLMs and LLMs may be trained on different data or follow different assumptions. Ensuring consistent behavior across the two layers can require extra tuning and validation.
Deployment Flexibility: SLMs can be containerized and deployed in a variety of environments. This modular setup helps separate different parts of the AI pipeline, making it easier to scale and manage them independently.
Integration Overhead: Coordinating two layers of intelligence isn’t just plug-and-play. It involves managing interfaces, latency limits, and fallback strategies. Without thoughtful design, this setup can quickly become tightly coupled, increasing the risk of cascading failures across the inference pipeline.
Use case – Hybrid AI Assistant
This use case introduces a Hybrid AI Assistant that combines the speed of a Small Language Models with the power of a Large Language Models. It uses the SLM to quickly classify incoming queries, then dynamically chooses between a local LLaMA model or OpenAI’s GPT model to handle the response, depending on the situation. The Hybrid AI Assistant is built using modular services that communicate via gRPC.
The entire architecture is containerized using Docker Compose, making it easy to launch and manage the full stack, including models, back-end services, and the user interface, within a consistent development or deployment environment.
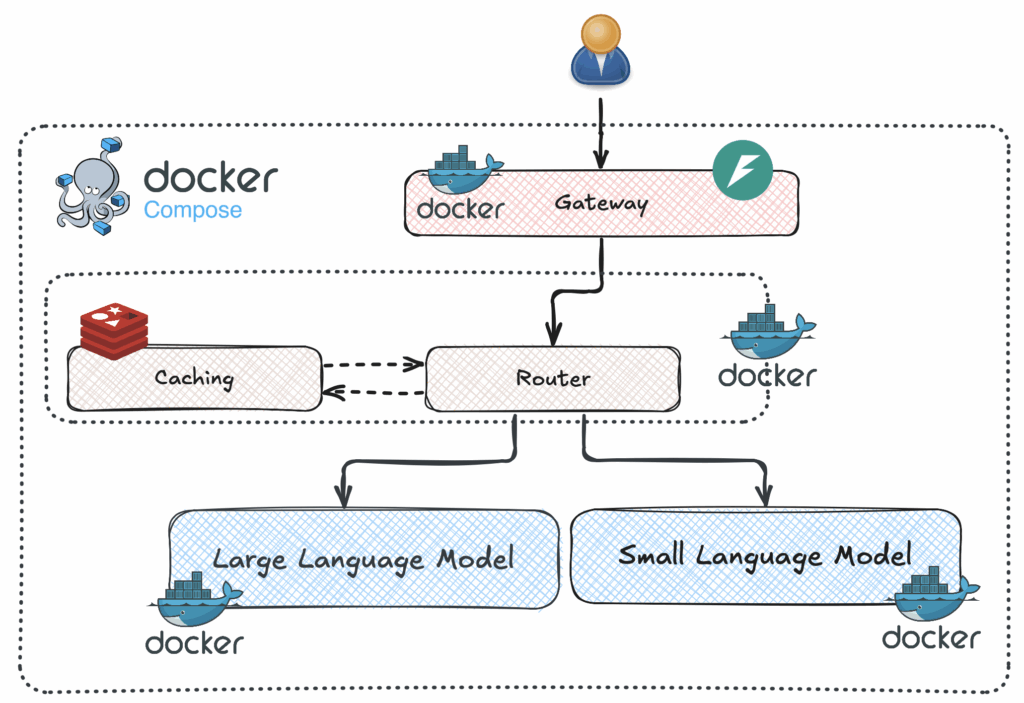

At the core is a Router Service that decides which model to use based on the SLM’s confidence and the user’s model preference. To boost efficiency, the Router also integrates a Redis cache, allowing it to reuse answers for repeated queries and avoid unnecessary processing.
A FastAPI-based gateway handles incoming HTTP requests from clients and forwards user queries to the Router Service using gRPC. It also attaches extra metadata, like the user’s chosen LLM backend, which gets passed along with the query.
On the frontend, a Streamlit app provides a simple interface where users can enter their queries, select a backend model ( local or OpenAI), and view the assistant’s response in real time. The response includes the answer, a confidence score, and the model that generated it. This setup enables users to switch between backends on the fly, without needing to restart or reconfigure any services.
The LLM services operate independently. llm_service_local generates responses using a quantized LLaMA model via llama-cpp-python, while llm_service_openai connects to the OpenAI API for its responses. Both services share the same gRPC interface, defined in a common assistant.proto file, which allows the Router to switch between them seamlessly based on the user’s choice.
The SLM service is a specialized service that uses a lightweight, pre-trained transformer model to classify user intent. It receives incoming queries from the Router Service via gRPC and responds with an intent prediction and a confidence score. If the confidence score exceeds a set threshold , the Router considers this response final and skips sending the query to the more resource-intensive LLM.
Source Code
To gain a better understanding of this simplified SLM + LLM application (Smart AI Assistat), take a look at the Source Code in my repository.
Wrapping Up
Hybrid Intelligence in Action – How to Deploy AI Solutions explores how to build AI systems that blend the speed and efficiency of Small Language Models (SLM) with the deeper reasoning capabilities of Large Language Models (LLM). In this setup, the SLM serves as the first line of response; quickly and efficiently handling common, well-defined user requests like greetings or basic FAQs. Because these lightweight models use fewer resources, they can even run on edge devices or in environments with limited computing power.
When the SLM isn’t confident in its response or runs into a question that’s outside its scope, it hands off the request to a more capable language model. This could be a local LLaMA model for offline tasks or an API-based model like OpenAI’s GPT-3.5 for more advanced reasoning and text generation.
Hybrid Intelligence not as a theoretical concept, but as a practical, deployable solution that balances speed, cost, privacy, and capability, ready for real-world use in support bots, assistants, or workflow automation tools.
- This model is a distilled version of the BERT base model. It was introduced in this paper. ↩︎


