Addressing Unexpected Outcomes
As explained in Part One, the SEDA framework consists of four steps, each of which was briefly discussed. The third step, Addressing Unexpected Outcomes, is what we’ll explore in detail in this article and consists of 2 parts:
- Vigilance Over Emergent Behaviors
- Cultivate Feedback-Driven Workflow

Precisely speaking, Section 4 covers the third step in the four-part SEDA framework. It focuses on strategies for managing unexpected outcomes that may arise during Software Transformation initiatives

Vigilance Over Emergent Behaviors
In Sociotechnical Systems, where software, people, and processes are tightly connected, unexpected behaviors often emerge from the way these parts interact. These behaviors aren’t planned or designed; they simply arise as the system grows and evolves.
Keeping an eye on these emergent behaviors is important. They can reveal hidden issues, shifting user needs, or unintended side effects of earlier design choices.
Staying vigilant means continuously watching how the system behaves across different areas, spotting patterns or oddities that may not stand out on their own, and stepping in early to keep things on track. It’s a move away from fixed design thinking toward a more flexible, real-time approach.
For this reason, in SEDA, we investigate two topics to stay Vigilant Over Emerging Behavior of system:
- Cross-Domain Interaction
- Post-Transformation Evolution
Cross-Domain Interaction
Different areas in software ecosystem, like development, operations, user experience, and business logic, are usually built with their own goals and constraints in mind. Each of these parts might work well on its own, but when they’re brought together, unexpected behaviors can emerge. These surprises often come from interactions between components, data flows, or team decisions that weren’t considered in the original design.
Monitoring how different parts of a system interact is essential for catching unintended side effects early. Instead of assuming that changes will only impact their specific area, teams should embrace a system-wide approach to observability, using tools like tracing, metrics, and strong cross-functional communication. This broader view helps uncover patterns or warning signs that something might be off, allowing teams to respond quickly.

Unintended Coupling: Even with the best intentions to keep systems modular and well-organized, domains often end up with hidden dependencies. These unseen connections can make the system less flexible and increase the risk of changes, since a change in one area might unexpectedly cause problems elsewhere.
Misaligned Objectives: When teams from different domains work toward conflicting KPIs or business goals, it can create friction and reduce efficiency. For example, a team focused on delivering features quickly might run into issues with another team prioritizing system reliability; ultimately hurting the overall harmony and performance of the system.
consistent Data Semantics: Different departments or systems often interpret the same data fields or events in different ways. For example, the term customer might mean one thing in billing and something else in CRM. These inconsistencies can cause integration problems, reduce data quality, and lead to poor decision-making.
Post-Transformation Evolution
Even after a transformation initiative wraps up, things don’t just stay the same, both the technology and the organization keep evolving. As teams start using new workflows, tools, and routines, unexpected behaviors can emerge. These new patterns often come from the complex mix of software systems, how people interact with them, and changes within the organization, like team restructures or shifts in how communication happens.
Here are the three most common patterns that often emerge during Post-Transformation Evolution.

Behavioral Drift: After a transformation, it’s common for teams and individuals to slowly slip back into old habits or create informal workarounds. Especially, if the new processes feel unfamiliar or overly complicated. Over time, this can weaken the purpose of the transformation and lead to a disconnect between how the system actually works and what it was meant to achieve.

Emergence of Hidden Dependencies: Sometimes, dependencies between teams, services, or domains aren’t obvious until the system is actually up and running. Once in use, these hidden connections can cause unexpected bottlenecks, delays, or risks, especially when a change in one area unexpectedly impacts others.

Tool–Process Mismatch: As the system grows and changes, the tools introduced during earlier stages of transformation may struggle to keep up. They might not scale effectively or adapt well to new business needs or evolving team dynamics. This can lead to friction, where tools and processes no longer work seamlessly together.

Cultivate Feedback-Driven Workflow
As systems evolve post-transformation, new behaviors, dependencies, and dynamics often emerge that were not fully anticipated during design. One of the most critical aspects of sustaining the value of transformation is maintaining awareness of how different components of the system interact, particularly across domain boundaries.
Transformation is NOT a one-time event, but the beginning of an ongoing journey.

To effectively navigate this evolving landscape, organizations must embed a feedback-rich culture at every level of the system. This involves creating mechanisms to capture and respond to insights from infrastructure, teams, users, and business performance in real-time.
The SEDA proposes best practices for cultivating this workflow across three main categories:
- Infrastructure Feedback Loops Between Domains
- Real-Time Monitoring of Business Metrics
- Gathering User Insight
Infrastructure Feedback Loops Between Domains
Creating feedback loops between different domains is necessary for keeping complex, distributed systems coherent and adaptable. When teams or systems work in isolation, important signals like performance slowdowns, latency spikes, or unusual user behavior, that can go unnoticed outside their immediate area.
By building feedback mechanisms that let operational and performance data flow across domain boundaries, organizations foster cross-functional awareness. This not only improves collaboration but also leads to faster, more informed decision-making. There are two types of feedback loops, and we’ll explore each with a real-world example below.
Negative Feedback Loops (System Stabilization)
Negative feedback loops are mechanisms that monitor changes in a system’s behavior and respond by making adjustments to keep the system stable. They used to stabilize or balance the software ecosystem1.
Their purpose is to maintain balance and prevent the system from spiraling out of control or becoming unstable. Key characteristics of Negative feedback loops are:
- They work to counteract change rather than amplify it.
- Think of them as a brake system which helping to keep things stable and prevent runaway effects or breakdowns.
- When functioning properly, they’re often unnoticed. It means, only becoming obvious when they fail or go missing.
Negative feedback loops provide strategic value by enhancing resilience, ensuring predictability, and building confidence in a system’s ability to self-correct. They also form the foundation of observability and adaptive system governance.
Negative feedback loops Use Cases
Here is 3 most relevant use cases in real world:
- Autoscaling based on CPU usage: When CPU usage increases, the system automatically adds new instances to handle the load. Once the demand goes down, those extra instances are removed to save resources.
- Circuit breakers: If a service keeps failing, circuit breakers step in to temporarily stop calls to that service. This helps prevent cascading failures and gives the service time to recover.
- Alert thresholds: Alerts are triggered when certain performance metrics, like response time or error rate, go beyond set limits. This helps teams catch and fix issues before they become critical.
Real World Example
This diagram shows a Negative Feedback Loop between two domains: the Order Domain and the Inventory Domain. The purpose of this loop is to keep the system stable by making sure it doesn’t try to process orders that can’t be fulfilled.
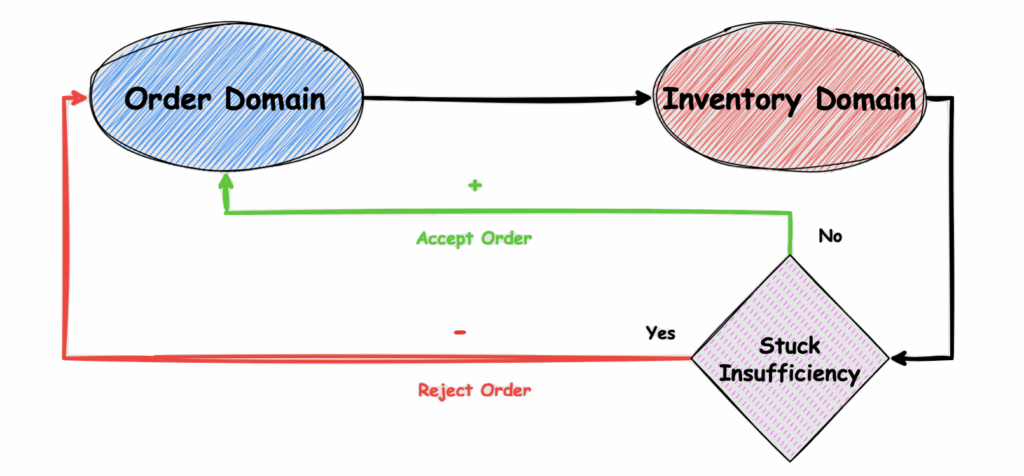
- The Order Domain initiates a request to place an order.
- The Inventory Domain then checks if there’s enough stock available.
- If the stock is insufficient, the process moves into a Stuck Insufficiency state.
- At this point, the system notifies the Order Domain to reject the order. This creates a Negative Feedback Loop that helps maintain system stability by avoiding overuse of resources or disappointing customers with unfulfilled orders.
Positive Feedback Loops (Reinforcement)
Positive feedback loops are processes that amplify change by reinforcing certain behaviors or patterns. This often leads to rapid growth or escalation. Their purpose is to build momentum, either in a positive direction or a negative one, depending on how the loop is managed2.
Key characteristics of Positive feedback loops are:
- Reinforces and encourages similar behavior over time.
- Can grow rapidly, leading to bigger impacts, both positive and negative.
- Requires careful monitoring to prevent things from getting out of hand.
Positive feedback loops provide strategic value by driving growth, innovation, and cultural momentum when effectively harnessed. However, they MUST be balanced with negative feedback loops to ensure healthy and sustainable progress.
Positive feedback loops Use Cases
- User engagement loops: As more people use the system and create content, it draws in even more users; creating a self-reinforcing cycle of growth and activity.
- Caching effectiveness: When certain data is accessed frequently, it’s more likely to stay in the cache. This speeds up performance, which in turn encourages even more access to that data.
- Deployment feedback: Faster deployments build team confidence, which leads to quicker iterations and an overall faster release cycle.
Real World Example
This diagram shows a Positive Feedback Loop between the Search Domain and the Recommendation Domain. In this loop, user behavior and system responses constantly influence each other, reinforcing and amplifying both personalization and engagement.
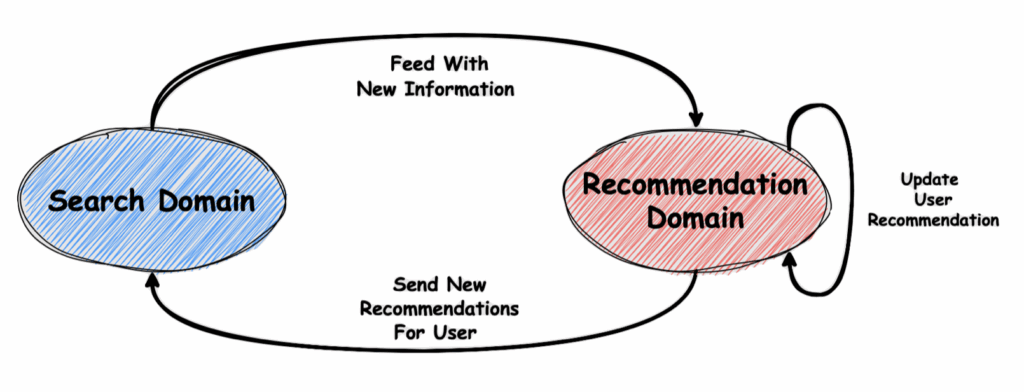
- When a user starts a search in the Search Domain, their input is captured.
- The Recommendation Domain analyzes this new search activity.
- Based on the latest data, updated recommendations are sent back to the Search Domain.
- As the user explores more relevant content, they stay engaged and continue searching. This ongoing interaction feeds back (Positive Feedback) into the system, helping it learn and continuously improve its recommendations over time.
Real-Time Monitoring of Business Metrics
Real-Time Monitoring of Business Metrics is essential for SEDA feedback-driven methodology. It allows organizations to see how software or operational changes directly affect real business outcomes. Rather than relying only on technical indicators like up-time or error rates, it shifts the focus to meaningful metrics like conversion rates, order success, customer churn, time to resolution, or how well new features are being adopted.
By tying monitoring efforts to business goals, teams can catch early signs of trouble, like a new feature that unexpectedly drives customers away or spot operational issues that traditional infrastructure metrics might miss.
When business metrics are tracked continuously and surfaced in real time, organizations can react quickly. Teams gain valuable insight into how system performance impacts revenue, customer experience, and operational effectiveness.
Gathering User Insight
Gathering user insights means regularly listening to and learning from the people who actually use your product. This includes direct feedback,like surveys, reviews, or support tickets, as well as indirect clues, such as how users navigate your app, where they click, or when they drop off.
By continuously feeding this information into product decisions and design, teams can shape software that truly reflects what users want and need. This user-first mindset helps create more intuitive, relevant experiences. Furthermore, over time, it builds trust and loyalty.
Wrapping Up
Addressing Unexpected Outcomes is an important part of Software Transformation, SEDA. No matter how well something is designed, it’s impossible to anticipate every behavior that might show up once real users, real data, and real-world conditions are involved.
The work doesn’t end when a system goes live. In fact, that’s when a new chapter begins. It’s a phase where close observation, thoughtful interpretation, and ongoing adjustment become essential. Over time, unexpected challenges tend to emerge:
- User behavior may shift.
- Tools may not fit as well as expected.
- Hidden dependencies can surface, especially as teams adapt to new processes.
A key strategy in managing these outcomes is embedding a feedback-driven culture throughout the organization.
- Negative feedback loops help keep things on track by correcting issues. For example, blocking new orders when inventory runs low.
- Positive feedback loops build on what’s working, like improving personalized recommendations based on user behavior.
By monitoring infrastructure and business metrics in real time, teams can spot these feedback signals early and respond quickly. Whether it means fixing a problem or doubling down on what’s working. It’s also important that these feedback loops are NOT siloed. They need to work across teams and functions, enabling shared insights and coordinated action.
- Negative feedback occurs when some function of the output of a system, process, or mechanism is fed back in a manner that tends to reduce the fluctuations in the output, whether caused by changes in the input or by other disturbances. Wikipedia ↩︎
- Positive feedback is a process that occurs in a feedback loop where the outcome of a process reinforces the inciting process to build momentum. Wikipedia ↩︎


