LLMOps, short for Large Language Model Operations, is a growing field that focuses on managing the entire lifecycle of large language models like GPT, LLaMA, Claude, and Mistral.
Think of it as the Generative AI version of MLOps: it brings together best practices from software engineering, DevOps, and machine learning operations, but tailors them specifically to the unique demands of large language models.
LLMOps involves everything from training and fine-tuning to deploying, monitoring, and optimizing these models in real-world applications. It also includes prompt engineering, data governance, and setting up feedback loops to keep systems learning and improving over time. The goal is to build LLM-powered systems that are reliable, scalable, secure, and always getting better.
LLMOps, Benefits & Barriers?
Today, we’ve reached a turning point. Large Language Models, as the complementary of SLMs, are no longer just research projects; they’re now at the core of real-world tools, from customer support and coding assistants to enterprise search and creative writing.
Without strong LLMOps practices in place, companies risk launching AI systems that are fragile, unsafe, or difficult to troubleshoot and that can quickly become costly to operate. But bringing these models into production isn’t simple.

Unlike traditional machine learning models, which are often static once deployed, LLMs need constant fine-tuning, not just of the models themselves, but also of the prompts, data pipelines, and system integrations. Their cost, complexity, and unpredictable behavior mean we need a more structured, thoughtful approach.
LLMOps brings its own set of infrastructure challenges. Running Large Language Models in production isn’t as simple as flipping a switch; it often requires massive GPU clusters, low-latency serving, support for multi-modal inputs, and highly parallelized pipelines for both inference and retrieval.
Last but not least, LLMOps is becoming increasingly important as issues like AI governance1, privacy, and safety move from nice to have to absolutely essential. Organizations need clear, structured ways to monitor and manage things like toxicity, bias, hallucinations, and misuse in large language models.
Just like CI/CD pipelines revolutionized software development by bringing structure and reliability, LLMOps is doing the same for AI. It makes sure it’s deployed responsibly and safely.
LLMOps Architecture and Lifecycle
Deploying a Large Language Models isn’t as simple as just calling an API. Behind the scenes, it requires a sophisticated system of tools, processes, and best practices to deliver performance, reliability, compliance, and real value to users. That’s where LLMOps architecture comes in.
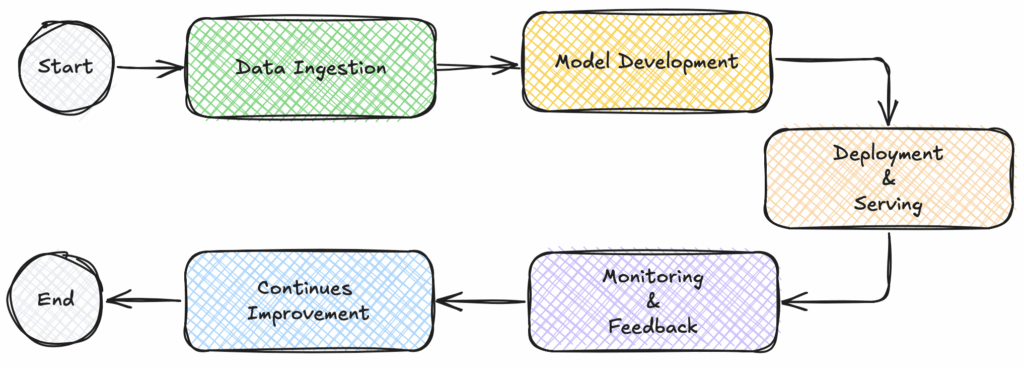
At a high level, the LLMOps lifecycle includes five core stages:
Data Ingestion
This stage is all about preparing the data; collecting, cleaning, and organizing it. So it can be used to fine-tune a Large Language Model or enhance its output through techniques like RAG2. The data can come from a variety of sources, such as documents, chat logs, code repositories, user inputs, or the web.
The key priorities here are data quality, consistent formatting, proper labeling (if needed), and removing any sensitive information.
Model Development
Model development focuses on choosing the right model and tailoring it to fit specific use cases. That could mean fully fine-tuning the model with new data, or using more efficient techniques like LoRA3, QLoRA4, or prompt-based tuning.
In some cases, fine-tuning isn’t necessary at all. Instead, developers rely on prompt engineering to guide the model’s behavior. This stage often involves experimenting with different configurations, prompt formats, and dataset sizes to find the best balance between performance, cost, and relevance. Evaluation and model selection also play a key role here.
Deployment & Serving
Once the model or prompt pipeline is ready, the next step is to deploy it into a production environment so it can start handling real user requests. This involves setting up infrastructure like model servers, creating APIs or SDKs, and configuring systems for auto-scaling, GPU usage, and fast, reliable responses.
At this stage, architects also need to make important decisions, like whether to use cloud-based APIs or host the models themselves, while balancing factors like performance, cost, and scalability.
Monitoring & Feedback
Once a model is deployed, ongoing monitoring becomes essential. It’s important to track both system-level metrics, like latency and error rates, and model-specific signals, such as hallucinations, toxic outputs, or off-topic responses.
Tools like Arize and PromptLayer can help by logging interactions, tracing prompt histories, spotting anomalies, and visualizing trends. This kind of active monitoring allows teams to quickly catch and address any issues or unexpected behavior changes.
Continuous improvement
The final stage focuses on using feedback, performance metrics, and fresh data to continuously improve the system. This could mean retraining the model, tweaking prompt templates, refining how information is retrieved, or adjusting how results are ranked and filtered.
Automation pipelines help streamline this process, enabling CI/CD for LLMs, new data flows in, models and prompts get updated, tested, and deployed with minimal disruption.
Developer & Architect Perspectives
While traditional ML pipelines mainly focus on training and validating models, LLMOps goes a step further. It also prioritizes real-time inference optimization, prompt engineering, and implementing ethical and safety measures, making it better suited for the dynamic nature of language model applications.
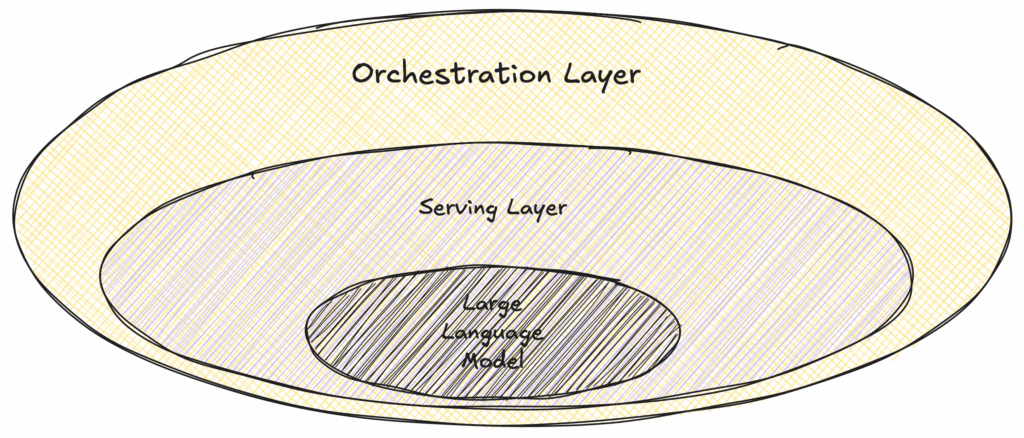
From an architectural perspective, a production-ready LLM system is made up of 3 key layers working together.
- At the heart of the system is the LLM itself: This could be an open-source model running on your own infrastructure, like LLaMA or Mistral, or a commercial model accessed via APIs such as OpenAI’s GPT.
- Surrounding the core model is the serving layer: This layer ensures the system can handle requests efficiently and at scale. Tools like vLLM or Triton Inference Server are commonly used here. This layer often integrates with RAG systems.
- On top of everything sits the prompt orchestration layer: It is managed by frameworks like LangChain or LlamaIndex. This part of the stack handles how prompts are built, routed, and executed across your application, helping coordinate complex workflows and ensuring consistent results.
For developers, the workflow in modern AI development looks very different from traditional machine learning. Instead of retraining models from the ground up, the focus is on refining prompts often through few-shot or zero-shot examples to shape how the model responds. This shift has created a need for specialized tools to manage prompt versions, run experiments, and evaluate results. Platforms like PromptLayer and DeepEval have become key parts of the developer toolkit. Observability is also critical. Developers need visibility into things like hallucinations, latency, and how effective prompts are.
Meanwhile, architects are focused on designing systems that can scale with demand while staying cost-effective and compliant. They face key decisions, like whether to use managed API services or run LLMs on their own infrastructure with GPUs or inference-optimized run-times.
LLMOps Stack
The LLMOps ecosystem is evolving quickly, with a growing number of tools designed to support every stage of the LLM lifecycle. These tools are making it easier for developers and architects to deploy and manage LLMs in production-ready environments.
Below, we’ve categorized the most relevant tools by their core functions and explained how each one fits into the broader architecture.
- Model Training: If you’re working with open-source LLMs, having the right tools for training and fine-tuning is essential.
- Hugging Face Transformers provides easy APIs for fine-tuning models with full or parameter-efficient techniques like LoRA or QLoRA.
- DeepSpeed optimizes large-scale training by enabling model parallelism and memory efficiency.
- Serving & Inference: In LLMOps, one of the toughest challenges is delivering large models quickly and efficiently, without sacrificing performance.
- vLLM, developed at UC Berkeley, uses a technique called PagedAttention5 to deliver fast, efficient inference, even when serving multiple users at once.
- NVIDIA‘s Triton Inference Server supports multiple back-ends like TensorRT, ONNX, and PyTorch, making it a powerful solution for high-performance GPU-based inference.
- Ray Serve and BentoML are scalable, Python-native tools that make it easy to deploy AI microservices and serve multiple models through a unified API.
- Prompt Engineering & Orchestration: Prompt logic and chaining are essential for building effective LLM applications. Here are some tools that help developers manage this layer:
- LangChain is a leading framework for managing prompts, building AI agents, and connecting with vector databases.
- LlamaIndex helps large language models connect to external knowledge sources, such as documents and databases.
- PromptLayer & OpenPrompt offer tools for logging, versioning, and testing prompts, making it easier to experiment and iterate effectively.
- Evaluation and Feedback: Traditional accuracy metrics alone aren’t enough to evaluate LLM outputs. So, new tools have emerged to fill the gap.
- DeepEval makes it easy to automatically evaluate LLMs for relevance, coherence, and accuracy.
- TruLens and LLM Studio make it easy to evaluate multiple metrics, gather human feedback, and score model alignment.
- Monitoring & Governance: These steps are crucial for ensuring observability and safety in production.
- Platforms like Arize AI, WhyLabs, and Humanloop help ensure the quality of LLM outputs by monitoring user interactions, detecting drift, and spotting potential hallucinations.
- To protect user privacy, tools like Presidio or PII scrubbers can be used to automatically remove sensitive information from user input.
Together, these tools form the foundation of the modern LLMOps stack. While no single tool can do it all, understanding how they work together is essential.
For architects, the priority is selecting scalable infrastructure and seamless integration points. For developers, on the other hand, it’s about choosing the right frameworks to move quickly and build safely.
LLMOps Use Cases
LLMOps isn’t just a concept; it’s already driving real-world innovation across industries. From smart chat-bots and automated document workflows to powerful AI copilots, organizations are using large language models to boost efficiency and unlock new possibilities. Here are some of the most impactful use cases, and how LLMOps helps bring them to life at scale.

AI Customer Support Assistants
One of the most common and impactful uses of Large Language Models is in automated customer support. Companies like Zendesk leverage fine-tuned LLMs to provide fast, helpful, and context-aware responses in live chat conversations.
To ensure these systems work effectively, LLMOps play a crucial role. This includes managing different prompt versions for specific use cases, monitoring responses in real time to catch hallucinations or off-brand replies, and incorporating feedback from human agents to continually improve and guide the model’s behavior.
Retrieval-Augmented Search for Enterprises
Enterprise search has taken a major leap forward with the rise of RAG. Technologies like LlamaIndex and LangChain make it possible to fetch relevant documents, enrich prompts with useful context, and generate accurate, natural-sounding responses.
For instance, PwC developed an internal Q&A bot for compliance using Azure OpenAI and vector search. Similarly, tools like Notion AI and Glean harness RAG to provide powerful knowledge search across internal documentation.

Code Generation and Developer Productivity
Tools like GitHub Copilot, and Amazon CodeWhisperer are reshaping the way software is built. These AI assistants can automatically generate code, fix bugs, and suggest improvements.
Behind the scenes, they rely on fine-tuned models trained on language-specific code datasets. They also use techniques like prompt orchestration to understand the developer’s context.
Telemetry data and RLHF6 help refine their suggestions over time. Meanwhile, LLMOps practices ensure that the models continue to improve while minimizing security risks and preventing faulty code from reaching production.

Legal & Contract Analysis
Legal teams are increasingly using LLMs to streamline their work, summarizing contracts, identifying potentially risky clauses, and extracting key terms. Some startups offer AI copilots tailored for law firms and enterprises.
To be effective and compliant, these systems typically require custom fine-tuning on legal datasets, specialized prompt templates for different contract types, and robust logging and explain-ability features to meet regulatory and compliance standards.
These use cases show how LLMOps forms the foundation of production-ready Large Language Model systems. Whether it’s powering customer experiences, legal tech, developer tools, or content moderation, the key to success lies in the ability to iterate quickly, deploy safely, and monitor consistently. That’s what sets real-world LLM applications apart from experimental prototypes.
LLMOps Onboarding
Bringing LLMs into production is about more than just calling an API. It’s about creating a system that can scale, adapt, and stay reliable over time. Whether you’re a developer building an AI-powered feature or an architect designing an enterprise-level AI platform, embracing LLMOps from the start can help you move faster, minimize risk, and achieve better results. Here’s the steps to start it.

Before jumping into infrastructure, start by identifying a focused use case where Large Language Models can clearly add value, like summarizing documents, answering user questions, or drafting content.
Steer clear of building broad, general-purpose AI agents right away; they’re tough to maintain without mature tooling.
Once you’ve nailed down the use case, keep your tech stack lean. For early prototyping, use managed APIs like OpenAI, Claude, or Gemini.
If your project involves working with documents or tools, consider adding frameworks like LangChain or LlamaIndex. And don’t forget to log all interactions with tools like PromptLayer to ensure traceability and better debugging down the line.

Prompts are the logic layer of your LLM application. As a developer, you should approach them with the same care and discipline as software code. That means storing prompts in Git, versioning them based on features or user segments, running A/B tests to evaluate changes, and tracking performance over time.
Use tools like PromptLayer, TruLens, or even a simple internal dashboard to log prompts, outputs, user feedback, and errors. This kind of data is crucial for effective iteration and improvement.
If you’re designing the system architecture, make sure there’s a centralized prompt registry or service in place. It should manage templates, access controls, and fallback logic, especially important when working with large or distributed teams.

Production LLM systems are naturally unpredictable, so observability isn’t optional, it’s essential from day one. Start by monitoring key metrics like latency, error rates, user feedback, and token usage. Set up alerts for anomalies, such as unusually long responses or frequent fallback behavior.
Collect user feedback regularly, whether it’s explicit like thumbs up/down or implicit such as users dropping off or rephrasing their inputs.
Tools like Arize AI, Humanloop, and DeepEval can help you understand how your system is performing and where it’s starting to break down.
Over time, this feedback loop powers better prompts, cleaner data, and even model retraining.

As your use case matures and traffic increases, you might consider transitioning from managed APIs to self-hosted models, such as Mistral, LLaMA, or Mixtral to reduce costs or enhance data privacy.
When moving to a self-hosted setup, it’s important to plan for multi-tenancy, load balancing, and secure data handling. Containerized environments like Kubernetes or Docker, along with orchestration platforms such as Ray or BentoML, can help ensure your infrastructure remains scalable and reliable.

Large Language Models are incredibly powerful tools, but they’re not perfect. They can make subtle mistakes, such as generating hallucinations, reflecting biases, producing toxic content, or being misused. Practicing responsible LLM operations means actively working to prevent these issues. This includes:
- Red-teaming prompts to test edge cases and identify prompt injection vulnerabilities
- Using moderation tools or classifiers to catch harmful content
- Logging all requests and responses for traceability and auditability
- Clearly documenting prompt intent, training data sources, and model versions
Developers should keep a detailed change log of prompt updates to track how interactions evolve over time. Meanwhile, architects must embed governance frameworks, like access control, transparency, and data anonymization into the design from the start.
Wrapping Up
LLMOps isn’t just a nice-to-have anymore, it’s essential for any team building applications powered by Large Language Models. It equips developers with the tools they need to move fast, while giving architects the guardrails to manage risk, performance, and cost.
By starting small, taking prompts and evaluations seriously, and scaling thoughtfully, teams can confidently integrate language models into their workflows.
- AI governance refers to the processes, standards and guardrails that help ensure AI systems and tools are safe and ethical. IBM ↩︎
- Retrieval-augmented generation is a technique for enhancing the accuracy and reliability of generative AI models with information from specific and relevant data sources. NVIDIA ↩︎
- LoRA is an improved fine-tuning method where instead of fine-tuning all the weights that constitute the weight matrix of the pre-trained large language model, two smaller matrices that approximate this larger matrix are fine-tuned. databricks ↩︎
- QLoRA is an even more memory efficient version of LoRA where the pretrained model is loaded to GPU memory as quantized 4-bit weights, while preserving similar effectiveness to LoRA. databricks ↩︎
- PagedAttention is an innovative technique, proposed by Kwon et al., that aims to dramatically reduce the memory footprint of LLM KV caches so to help make LLMs more memory-efficient and accessible. Hopeswork ↩︎
- Reinforcement learning from human feedback (RLHF) is a machine learning ML technique that uses human feedback to optimize ML models to self-learn more efficiently. AWS ↩︎


